Prologをほとんど知らない私がRuby-Prologを使ってみたメモ。
まずは基本的な使い方。
require "ruby-prolog"
c = RubyProlog::Core.new
c.parent["Ieyasu", "Hidetada"].fact
c.parent["Hidetada", "Iemitsu"].fact
c.grandpa[:X, :Y] << [c.parent[:X, :Z], c.parent[:Z, :Y]]
p c.query(c.grandpa[:X, :Y])
#=> [[grandpa["Ieyasu", "Iemitsu"]]
いちいちc.って書くのが面倒なときはinstance_evalを利用する。irbで試すときはc.ってつけて一行ずつ処理した方が分かりやすい。
c.instance_eval do
parent["Ieyasu", "Hidetada"].fact
parent["Hidetada", "Iemitsu"].fact
grandpa[:X, :Y] << [parent[:X, :Z], parent[:Z, :Y]]
query grandpa[:X, :Y]
end
queryメソッドは内部的にresolveメソッドを呼び出している。resolveメソッドの挙動について調べる。
c.resolve(c.parent[:X, :Y]){|env| p env[:X]}
#=> "Hidetada"
"Iemitsu"
c.resolve(c.parent[:X, :Y]){|env| p env["Ieyasu"]}
#=> "Ieyasu"
"Ieyasu"
c.resolve(c.parent[:X, "Iemitsu"]){|env| p env[:X]}
#=> "Hidetada"
c.resolve(c.grandpa[:X, "Iemitsu"]){|env| p env[:X]}
#=> "Ieyasu"
要するに、与えた式が成り立つ状況をリストアップしてブロックを実行する。状況はenvという変数でブロックに渡され、env[:X]のようにしてその状況における変数:Xの値を調べることができる。env["Ieyasu"]のようにシンボル以外の引数を渡したときには引数がそのまま戻ってくる。
2013年12月2日月曜日
2013年6月28日金曜日
LaTeXで概念構造を書くためのマクロ
プリアンブルで以下のように書く。
\makeatletter使い方
\def\jcat#1{\vbox{\hbox{$_\textrm{\rm\scriptsize\mathstrut#1}$}\hrule height 0pt}}
\def\jlist#1{\vbox{\@for\i:=#1\do{\hbox{$\mathstrut$\textsc{\i}}}\hrule height 0pt}}
\def\jarg#1#2{$\left[\vcenter{\hbox{\jcat{#1} \jlist{#2}}}\right]$}
\def\jfunc#1#2{#1$\left(\vcenter{\hbox{#2}}\right)$}
\makeatother
\jarg{Object}{car,red}結果
\jfunc{have}{John, car}
\jarg{Event}{\jfunc{have}{\jarg{Object}{John},\jarg{Object}{car,\jarg{Property}{red}}}}
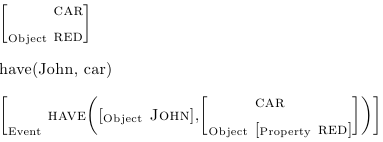
- かっこは数式モードの\left[や\right]などで書く。
- かっこのすぐ内側には\vcenterを置く。
- ( )の内側は\vboxでもいいかも。
- \vcenterや\vboxの内側には\hboxと\hruleのみ置く。
- vbox系は内部のhboxの幅に応じて自動的に横幅が決まる。
- hboxを置かずに直接文字などを置くと横幅が行幅いっぱいに広がる。
- \vbox内の最後には高さ0の\hruleを置く。
- ベースラインをそろえるため。
- 高さ0にするのは不可視にするため。
- 文字列を置く可能性のある場所には$\mathstrut$を置く。
- 行高を確保してレイアウト崩れを防ぐ。
2012年7月26日木曜日
Rubyでフック処理
ここ2日ほどフック処理をするためのモジュールを作ろうとして四苦八苦していた。あちこち検索していろんなソースを参考にしつつ、とりあえずこんな感じになった。
どういうときに使うかというと、例えばArrayクラスを継承したMyArrayクラスを定義して、MyArray#mapの戻り値をArrayではなくMyArrayで受け取りたい、というような場合に使う。普通にクラスを継承させただけでは、MyArray#mapの戻り値はArrayオブジェクトになる。
Hookerモジュールを使うと、次のように#mapの戻り値をMyArrayオブジェクトで返すMyArrayクラスを定義することができる。
おおまかな使い方としては、define_hookメソッドでフックしたいメソッドをオーバーライドする。define_hookの引数はフックしたいメソッドの名前で、ブロックはフック処理である。ブロックの第一引数origはsuperをProc化したものである(定義ブロック内ではsuperが使えないのでこのような方法を取っている)。ブロックの第二引数以降では*argsや&blockなど、メソッドに渡したい引数を与えることができる。引数を加工した上で元メソッドに引き渡したい時は、argsやblockを加工した上でorig.call(*args, &block)などとする。メソッドの戻り値を加工した上で取得したい時は、orig.callの戻り値を加工する。上記では、mapの戻り値を加工してArrayからMyArrayに書き換えている。
別の使い方としては、eachメソッドをフックして#eachのブロックの引数を加工することもできる。
手こずったポイントの一つは、define_hookに渡す定義ブロックが、クラスのコンテキストで生成されてしまうということ。このため、定義ブロック内でselfを使うとインスタンス(=ary)ではなくクラス(=MyArray)を参照してしまうという問題が生じた。そこでinstance_execを使って定義ブロック(=&hook)を強制的にインスタンスのコンテキストで実行することを考えたが、instance_execは&hookに引数を引き渡すことはできるものの、ブロックの引渡し方がよく分からない。このため、eachなどブロックを取るメソッドをフックしたいときに、このブロックをどうやって&hookに引き渡せばいいかで悩むことになった。最終的に、instance_execのソースを探してきて、似たようなコードを自前で書くことによって問題を解決した。あとはsuperが使えるようになれば、もっと直感的な使い勝手になると思うのだが・・・。
module Hooker
def self.included(klass)
klass.extend(ClassMethods)
klass.__send__ :include, InstanceMethods
end
module ClassMethods
def define_hook(name, &hook)
define_method(name) do |*args, &block|
singleton_class =(class << self; self; end)
singleton_class.module_eval{define_method(:__instance_exec, &hook)}
orig = proc{|*args, &block| super(*args, &block)}
begin
return send(:__instance_exec, orig, *args, &block)
ensure
singleton_class.module_eval{remove_method(:__instance_exec)} rescue nil
end
end
end
end
module InstanceMethods
end
end
どういうときに使うかというと、例えばArrayクラスを継承したMyArrayクラスを定義して、MyArray#mapの戻り値をArrayではなくMyArrayで受け取りたい、というような場合に使う。普通にクラスを継承させただけでは、MyArray#mapの戻り値はArrayオブジェクトになる。
class MyArray < Array
end
ary = MyArray.new([1,2,3])
new_ary = ary.map{|n| n + 1}
puts new_ary.class #=> Array
Hookerモジュールを使うと、次のように#mapの戻り値をMyArrayオブジェクトで返すMyArrayクラスを定義することができる。
class MyArray < Array
include Hooker
define_hook(:map){|orig, &block| self.class.new(orig.call(&block))}
end
ary = MyArray.new([1,2,3])
new_ary = ary.map{|n| n + 1}
puts new_ary.class #=> MyArray
おおまかな使い方としては、define_hookメソッドでフックしたいメソッドをオーバーライドする。define_hookの引数はフックしたいメソッドの名前で、ブロックはフック処理である。ブロックの第一引数origはsuperをProc化したものである(定義ブロック内ではsuperが使えないのでこのような方法を取っている)。ブロックの第二引数以降では*argsや&blockなど、メソッドに渡したい引数を与えることができる。引数を加工した上で元メソッドに引き渡したい時は、argsやblockを加工した上でorig.call(*args, &block)などとする。メソッドの戻り値を加工した上で取得したい時は、orig.callの戻り値を加工する。上記では、mapの戻り値を加工してArrayからMyArrayに書き換えている。
別の使い方としては、eachメソッドをフックして#eachのブロックの引数を加工することもできる。
class MyArray < Array
include Hooker
define_hook(:each){|orig, &block| orig.call{|x| block.call(self.class.new(x))}}
end
ary = Bar.new([[1,2,3], [4,5,6], [7,8,9]])
ary.each{|x| puts "#{x}:#{x.class}"}
#=>
[1, 2, 3]:MyArray
[4, 5, 6]:MyArray
[7, 8, 9]:MyArray
手こずったポイントの一つは、define_hookに渡す定義ブロックが、クラスのコンテキストで生成されてしまうということ。このため、定義ブロック内でselfを使うとインスタンス(=ary)ではなくクラス(=MyArray)を参照してしまうという問題が生じた。そこでinstance_execを使って定義ブロック(=&hook)を強制的にインスタンスのコンテキストで実行することを考えたが、instance_execは&hookに引数を引き渡すことはできるものの、ブロックの引渡し方がよく分からない。このため、eachなどブロックを取るメソッドをフックしたいときに、このブロックをどうやって&hookに引き渡せばいいかで悩むことになった。最終的に、instance_execのソースを探してきて、似たようなコードを自前で書くことによって問題を解決した。あとはsuperが使えるようになれば、もっと直感的な使い勝手になると思うのだが・・・。
2012年7月23日月曜日
RubyのDelegatorを使ってみる話
例えば、Arrayクラスにhelloというメソッドを追加したい場合、次のようなやり方ができる。
class Array
def hello
puts "Hello world !!"
end
end
しかし、もともとあるArrayクラスに手を加えたくない場合もある。いくつかやり方があるが、Arrayクラスを継承した別のクラスを定義するという方法がある。
class HelloArray < Array
def hello
puts "Hello world !!"
end
end
しかし、HelloArrayクラスのオブジェクトにmapなどのメソッドを使うと、Arrayクラスに戻ってしまう。
obj1 = HelloArray.new([1, 2, 3])
obj2 = obj1.map{|n| n + 1}
obj2.class # => Array
そこで、obj1に何か仕事をさせて、戻り値がArrayであれば自動的にHelloArrayにするという処理を実現したいとする。これはdelegateという標準ライブラリを使って次のように実現することができる。
require 'delegate'
class HelloArray < SimpleDelegator
def method_missing(name, *args, &block)
obj = super(name, *args, &block)
obj = HelloArray.new(obj) if obj.class == Array
return obj
end
end
obj1 = HelloArray.new([1, 2, 3])
obj2 = obj1.map{|n| n + 1}
obj2.class # => HelloArray
SimpleDelegatorはmethod_missingを利用してオブジェクトへの委譲を行う。そこで、SimpleDelegatorを継承したHelloArrayクラスを定義して、method_missingを書き換えることによって「ほとんど全てのメソッドを対象としたフック処理」を行うことができる。これにより、メソッドの戻り値がArrayかどうかを監視して、ArrayであればHelloArrayにするという処理を実現することができる。
これで、obj1によって生成されるArrayオブジェクトは全て自動的にHelloArrayオブジェクトになるようになったはずである。ところが、次のような処理はうまく行かない。
obj1 = HelloArray.new([[1,2,3],[4,5,6],[7,8,9]])
obj1.each{|item| item.hello}
itemには[1,2,3]や[4,5,6]や[7,8,9]が順番に代入されるが、これらはobj1のメソッドの結果として生成されるわけではないので、HelloArrayの監視対象ではない。そこでHelloArrayのeachメソッドを上書きして、これらの要素も監視するようにしよう。
class HelloArray
def each
super do |item|
item = HelloArray.new(item) if item.class == Array
yield item
end
end
end
これで、obj1.each{|item| ... }のitemも、自動的にArrayからHelloArrayに変換されるようになる。当然、eachメソッドを参照するEnumerable系のメソッド(mapとか)にも自動的に適用される・・・と思いきや、実はうまく行かない。
obj1.map{|item| item.hello} # => Error!
HelloArrayクラスにはmapは定義されていないので、method_missingを経由してArrayに委譲されることになる。ところが、Array#mapはあくまでArray#eachを参照するのであって、HelloArray#eachを再定義しても無視されるのではないかと思われる。ならばどうするのかというと、HelloArrayクラスにEnumerableをインクルードしてやる。
class HelloArray
include Enumerable
end
これで、HelloArray#mapその他が定義され、これらはHelloArray#eachを参照するので、mapも期待通り動作するようになる。が、今度はEnumerableがインクルードされてHelloArray#mapが定義されたことにより、method_missing経由でArray#mapが呼び出されなくなるので、method_missingで行なっていたmapの結果をHelloArrayに変換する処理が行われなくなってしまう。これを解決するには、デリゲーターを二重構造にするという方法がある。
class HelloArray < SimpleDelegator
def hello
puts "Hello World !!"
end
def method_missing(name, *args, &block)
obj = super(name, *args, &block)
obj = HelloArray.new(obj) if obj.class == Array
return obj
end
end
class HelloArrayInner < SimpleDelegator
include Enumerable
def each
super do |item|
item = HelloArray.new(item) if item.class == Array
yield item
end
end
end
obj1 = HelloArray.new([])
obj2 = HelloArrayInner.new(obj1)
これで、obj2#mapのブロック引数はHelloArrayになるし、戻り値もHelloArrayになる。最後に、obj1、obj2と二段階に分けてデリゲーターを生成するのは手間なので、一回ですむようにHelloArray#initializeを修正することにしよう。
class HelloArray
def initialize(obj)
super
self.__setobj__ HelloArrayInner.new(obj)
end
end
Delegator#__setobj__は委譲先オブジェクトを変更するメソッドである。ここではobjからHelloArrayInnner.new(obj)へと委譲先を差し替えることで、HelloArrayとobjの間にHelloArrayInnerをはさみこんでいる。これにより、次のような書き方で二重構造のデリゲーターを生成することができるようになる。
obj = HelloArray.new([])
class Array
def hello
puts "Hello world !!"
end
end
しかし、もともとあるArrayクラスに手を加えたくない場合もある。いくつかやり方があるが、Arrayクラスを継承した別のクラスを定義するという方法がある。
class HelloArray < Array
def hello
puts "Hello world !!"
end
end
しかし、HelloArrayクラスのオブジェクトにmapなどのメソッドを使うと、Arrayクラスに戻ってしまう。
obj1 = HelloArray.new([1, 2, 3])
obj2 = obj1.map{|n| n + 1}
obj2.class # => Array
そこで、obj1に何か仕事をさせて、戻り値がArrayであれば自動的にHelloArrayにするという処理を実現したいとする。これはdelegateという標準ライブラリを使って次のように実現することができる。
require 'delegate'
class HelloArray < SimpleDelegator
def method_missing(name, *args, &block)
obj = super(name, *args, &block)
obj = HelloArray.new(obj) if obj.class == Array
return obj
end
end
obj1 = HelloArray.new([1, 2, 3])
obj2 = obj1.map{|n| n + 1}
obj2.class # => HelloArray
SimpleDelegatorはmethod_missingを利用してオブジェクトへの委譲を行う。そこで、SimpleDelegatorを継承したHelloArrayクラスを定義して、method_missingを書き換えることによって「ほとんど全てのメソッドを対象としたフック処理」を行うことができる。これにより、メソッドの戻り値がArrayかどうかを監視して、ArrayであればHelloArrayにするという処理を実現することができる。
これで、obj1によって生成されるArrayオブジェクトは全て自動的にHelloArrayオブジェクトになるようになったはずである。ところが、次のような処理はうまく行かない。
obj1 = HelloArray.new([[1,2,3],[4,5,6],[7,8,9]])
obj1.each{|item| item.hello}
itemには[1,2,3]や[4,5,6]や[7,8,9]が順番に代入されるが、これらはobj1のメソッドの結果として生成されるわけではないので、HelloArrayの監視対象ではない。そこでHelloArrayのeachメソッドを上書きして、これらの要素も監視するようにしよう。
class HelloArray
def each
super do |item|
item = HelloArray.new(item) if item.class == Array
yield item
end
end
end
これで、obj1.each{|item| ... }のitemも、自動的にArrayからHelloArrayに変換されるようになる。当然、eachメソッドを参照するEnumerable系のメソッド(mapとか)にも自動的に適用される・・・と思いきや、実はうまく行かない。
obj1.map{|item| item.hello} # => Error!
HelloArrayクラスにはmapは定義されていないので、method_missingを経由してArrayに委譲されることになる。ところが、Array#mapはあくまでArray#eachを参照するのであって、HelloArray#eachを再定義しても無視されるのではないかと思われる。ならばどうするのかというと、HelloArrayクラスにEnumerableをインクルードしてやる。
class HelloArray
include Enumerable
end
これで、HelloArray#mapその他が定義され、これらはHelloArray#eachを参照するので、mapも期待通り動作するようになる。が、今度はEnumerableがインクルードされてHelloArray#mapが定義されたことにより、method_missing経由でArray#mapが呼び出されなくなるので、method_missingで行なっていたmapの結果をHelloArrayに変換する処理が行われなくなってしまう。これを解決するには、デリゲーターを二重構造にするという方法がある。
class HelloArray < SimpleDelegator
def hello
puts "Hello World !!"
end
def method_missing(name, *args, &block)
obj = super(name, *args, &block)
obj = HelloArray.new(obj) if obj.class == Array
return obj
end
end
class HelloArrayInner < SimpleDelegator
include Enumerable
def each
super do |item|
item = HelloArray.new(item) if item.class == Array
yield item
end
end
end
obj2 = HelloArrayInner.new(obj1)
これで、obj2#mapのブロック引数はHelloArrayになるし、戻り値もHelloArrayになる。最後に、obj1、obj2と二段階に分けてデリゲーターを生成するのは手間なので、一回ですむようにHelloArray#initializeを修正することにしよう。
class HelloArray
def initialize(obj)
super
self.__setobj__ HelloArrayInner.new(obj)
end
end
Delegator#__setobj__は委譲先オブジェクトを変更するメソッドである。ここではobjからHelloArrayInnner.new(obj)へと委譲先を差し替えることで、HelloArrayとobjの間にHelloArrayInnerをはさみこんでいる。これにより、次のような書き方で二重構造のデリゲーターを生成することができるようになる。
obj = HelloArray.new([])
2012年7月13日金曜日
正規表現とチョムスキー階層に関する簡単なまとめ
テキスト検索などに利用される正規表現は、チョムスキーのタイプ-3文法(正規文法)に由来する。チョムスキーは句構造文法をタイプ-0からタイプ-3までの4つの階層に分類した。
おおまかに言って、タイプ-1は左辺が複数ノードの場合もある句構造文法、タイプ-2は左辺が単一ノードの句構造文法、タイプ-3は二股枝分かれの句構造文法に相当する。このうち、正規表現はタイプ-3の正規文法に由来する。
(2012.8.5追記: タイプ-3は単なる二股枝分かれではなく、どちらか一方の枝が終端記号であるような二股枝分かれ)
実際に、簡単な正規表現を例にとって、それが正規文法でどのように表現されるか考えてみることにしよう。/ABC/という正規表現は、次のような句構造文法に対応する。
S1→A+S2
S2→B+S3
S3→C
正規表現でよく使われる繰り返し記号/*/、/+/、/?/などは次のような句構造文法で表現することができる。
/A*B/
S1→A+S1
S1→B
/A+B/
S1→A+S2
S2→A+S2
S2→B
/A?B/
S1→A+S2
S1→B
S2→B
実際には、最近の処理系で用いられる正規表現は、正規文法が本来表現できる範囲を超える文字列を表現できるとされる。が、大雑把な仕組みとしてはこんな感じである。
| タイプ-0 | - | 制限なし |
| タイプ-1 | 文脈依存文法 | αAβ→αγβ |
| タイプ-2 | 文脈自由文法 | A→γ |
| タイプ-3 | 正規文法 | A→aおよびA→aBまたはA→Ba |
おおまかに言って、タイプ-1は左辺が複数ノードの場合もある句構造文法、タイプ-2は左辺が単一ノードの句構造文法、タイプ-3は二股枝分かれの句構造文法に相当する。このうち、正規表現はタイプ-3の正規文法に由来する。
(2012.8.5追記: タイプ-3は単なる二股枝分かれではなく、どちらか一方の枝が終端記号であるような二股枝分かれ)
実際に、簡単な正規表現を例にとって、それが正規文法でどのように表現されるか考えてみることにしよう。/ABC/という正規表現は、次のような句構造文法に対応する。
S1→A+S2
S2→B+S3
S3→C
正規表現でよく使われる繰り返し記号/*/、/+/、/?/などは次のような句構造文法で表現することができる。
/A*B/
S1→A+S1
S1→B
/A+B/
S1→A+S2
S2→A+S2
S2→B
/A?B/
S1→A+S2
S1→B
S2→B
実際には、最近の処理系で用いられる正規表現は、正規文法が本来表現できる範囲を超える文字列を表現できるとされる。が、大雑把な仕組みとしてはこんな感じである。
2012年3月7日水曜日
gem作成に関するメモ
はじめてgemパッケージを作るにあたってやったことのメモ。
1. GitHubにアカウントを作る。
さらにログイン後に見ることができるチュートリアル(http://help.github.com/mac-set-up-git/)して、自分のPCにgitをインストールし、sshとかの設定をする。
2. 以下のサイトを読んでjewelerのセットアップやプロジェクトの作成をする。
http://technicalpickles.com/posts/craft-the-perfect-gem-with-jeweler/
jewelerのインストール。
gem sources -a http://gems.github.com
sudo gem install technicalpickles-jeweler
以下の設定は1.で既に終わっているはず。
$ git config --global user.email johndoe@example.com
$ git config --global user.name 'John Doe'
$ git config --global github.user johndoe
$ git config --global github.token 55555555555555
その後の新規プロジェクトの作成のところは別のサイトも参照しつつ3.で。
3. 以下のサイトを読んで新規プロジェクトの作成。
http://jp.rubyist.net/magazine/?0037-CreateRailsPlugin
ここではプロジェクト名をrenkonとし、ローカルの置き場は~/project/renkonとしておく。projectフォルダを作ってそこに移動し、以下のようにする。
$ jeweler --create-repo renkon
--create-repoは何回やってもタイムアウトして失敗するけど、ときどき成功するのでよく分からんまま先に進む。--rspecはrspec 1.3ではなく2.0がインストールされているとrakeのときにいろいろエラーが出るようなのではしょる。
公開準備。まずバージョンファイルを作る。
$ rake version:write
なんか警告が出るので、無視しても問題ないと思うが、Rakefileの以下の部分を書き換えておいた方がいいかも。
#require 'rake/rdoctask'
require 'rdoc/task'
公開準備。まずバージョンファイルを作る。
$ rake version:write
なんか警告が出るので、無視しても問題ないと思うが、Rakefileの以下の部分を書き換えておいた方がいいかも。
#require 'rake/rdoctask'
require 'rdoc/task'
バージョンを上げる。
$ rake version:bump:minor
ビルドする。上記サイトの指示通り、先にRakefileのsummaryとdescriptionのところを書き換えておく。
$ rake build
公開する。
$ git add .
$ git commit -m "create new library."
$ git push origin master
$ rake release
4. プロジェクトの更新
lib/renkon.rb
lib/renkon/subfile1.rb
みたいな感じでプロジェクトを作って更新していくものと思われる。
2012年2月8日水曜日
論文を書くときのフォントについて心得ておくべき3つのこと
Wordとかで論文を書くときのフォントについて心得ておくべきこと。
1. デフォルトに従え
長年コンピューターを使っていて得た教訓の一つは、特に必要のない限り、デフォルトから外れたことはしない方がいいということである。例えば、ソフトウェアをインストールするとき、わざわざインストール先フォルダをD:¥Appsとかに変えない方がいい。必要があればそうしても構わないが、そういうことをして後で面倒なことになったことは一度や二度ではない。フォントについても同じで、WindowsのWordで原稿を書け、と言われたら、たとえヒラギノの熱烈なファンであっても、素直にMS明朝を使っておくのが無難である。そうしておくことで、起こり得るかなりの種類のトラブル(例えば、全てMS明朝に直して再提出することを後から要求されたりとか)を事前に回避することができる。文書のところどころに標準的でないフォントを混ぜ込むようなことも、努々してはならない。どうしても特殊なフォントを使用しなければならないような場合には、Wordのファイルと一緒にフォントを埋め込んだpdfファイルも併せて提出しておいた方がいいだろう。印刷から出版まで全て自分の好きにできるような場合であれば、ご自由にどうぞ。
2. 等幅フォントを使え(日本語の場合)
原則として、Wordで原稿を書くときには、空白文字を使って位置調整することは邪道であり、タブとインデントを使用すべきである。にもかかわらず、等幅フォントを使っておくことで、レイアウト上の些細な問題を回避することができる場面が少なからず存在する。等幅フォントとは全ての文字の横幅が同じであるようなフォントのことである。これに対して、文字によって横幅が異なるフォントをプロポーショナルフォントと言う。
Windowsであれば、MSゴシックやMS明朝は等幅フォントであり、MS P ゴシックやMS P 明朝はプロポーショナルフォントである。ただしMS P ゴシックやMS P 明朝も漢字は全て横幅が同じであり、平仮名、カタカナ、英字など漢字以外の文字で横幅が変動する。ちなみにMacで使われるヒラギノやAdobeのソフトウェアについてくる小塚の場合は、漢字、平仮名、カタカナなどは等幅であるが、英字はプロポーショナルのようである。
欧文については、等幅フォントにこだわる必要はない。というより、欧文フォントは普通はプロポーショナルフォントである。後述するように、欧文フォントについてはTimesを使用することを推奨する。欧文の等幅フォントとしては、CourierやCourier Newが有名であり、プログラムのコードを記述する際などによく使われる。
3. Timesを使え(欧文の場合)
最初に、デフォルトに従えと言ったが、唯一デフォルトに逆らうべきであると思うのは欧文フォントの選択である。Wordのデフォルトの欧文フォントはCenturyだが、新規文書を開いたら最初にTimes New Romanに変更すべきである。Centuryがよくないと思う理由は2つある。第1に、Timesは斜体にしたとき、ちゃんと筆記体風のイタリック体になるが、Centuryは単純に斜めに傾けただけのオブリーク体になるだけで、ださい。第2に、Centuryはギリシャ文字の書体がださい。日本語環境のWordでは、ギリシャ文字はデフォルトでは日本語フォント(MS明朝とか)になってしまうが、手動で欧文フォントに変更することも可能であり、数式の中などで使う場合には当然、欧文フォントにすべきである。明らかに、CenturyよりTimesの方が、我々が(数式中の変数などとして)普段見慣れたギリシャ文字のイメージに近いと思うだろう。
ちなみに私はTeXを使うときにはTimesではなくPalatinoをよく使うが、これは日本語フォント(ヒラギノとか)との相性がTimesよりいいような気がするからである。欧文だけで文書を作るときにはPalatinoよりTimesの方が見やすいような気がする。
登録:
投稿 (Atom)